

Other recent blogs



Businesses are producing more data than ever, thanks to technologies like the Industrial Internet of Things (IIoT) and Generative Artificial Intelligence (GenAI).
According to Deloitte, “Manufacturing alone is estimated to generate about 1,812 petabytes (PB) of data every year, more than communications, finance, retail and several other industries.” In the Oil and gas industry, an offshore oil platform typically generates up to 2TB of data daily.
It’s a lot of data. And while generating massive amounts of data can help unlock new possibilities for an enterprise, it brings with it a new set of challenges.
To begin with, the traditional data warehouses, databases, and legacy data frameworks were not built to allow modern enterprises to collect, store, and process the troves of data that are produced by these entities nowadays. These systems are simply not agile enough to help you capture the opportunities of IIoT and machine-generated data.
It is, therefore, not enough to generate data at the speed of business. To harness its transformative potential while keeping costs under control, it is essential for organizations to build a secure, scalable, and cost-effective data storage and management platform. This is exactly where industry veterans begin to talk about solutions like data lake architecture.
Understanding a data lake architecture
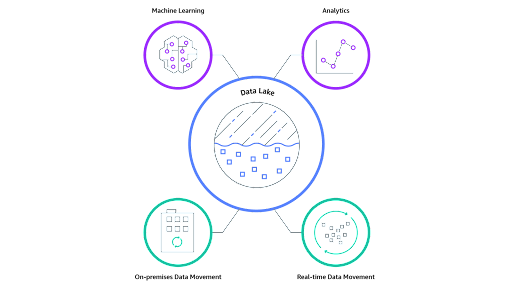
The primary aim or goal of a modern data lake architecture is to build a central repository to seamlessly and inexpensively store massive amounts of data gathered from numerous sources. Whether the data is unstructured, structured, or semi-structured, it can be safely stored in a data lake.
Over the years, leading-edge businesses across industries have made a strategic shift toward data lake architecture as the approach empowers businesses to derive valuable insights, improve decision-making, and facilitate advanced analytics by providing a centralized repository for data exploration and integration, fostering innovation and data-driven strategies across the organization.
.webp)
A data lake is not a data warehouse
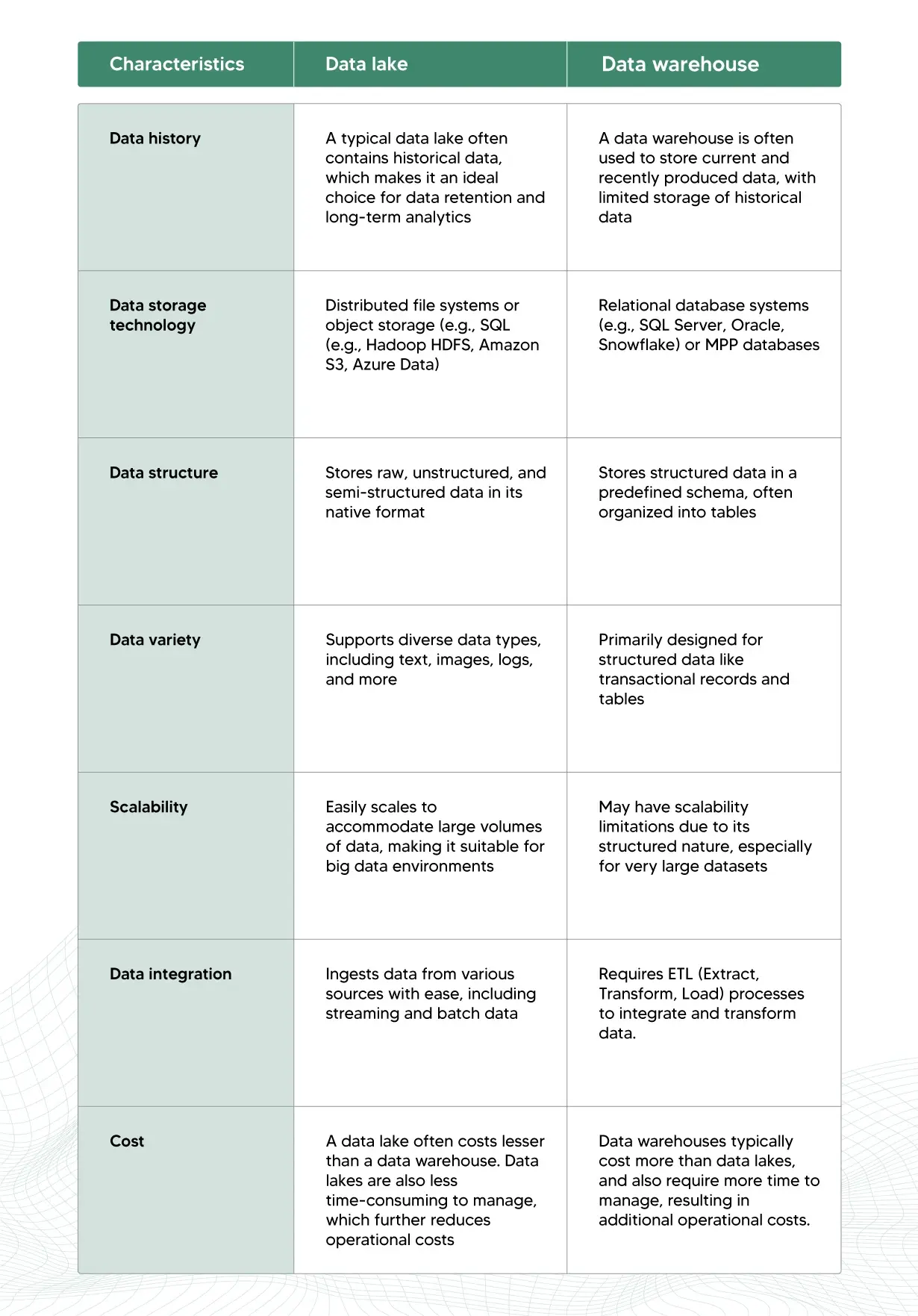
It’s no surprise that many in our industry often interchange a data lake as a data warehouse. Though both data storage solutions share some similarities, data lakes are significantly different from data warehouses.
A data lake is not a data warehouse; they are fundamentally different in their approach to data management and storage.
While a data warehouse is structured and designed to store data in a predefined schema optimized for querying and analysis, a data lake, on the other hand, is more like a vast, unstructured reservoir that holds raw and diverse data in its native format.
Read about 9 industry-leading data warehousing tools in this blog
Why do you need a data lake?
Organizations looking to harness greater value from data have better chances of outperforming the competition and fortifying their bottom lines. A data lake, therefore, emerges as a critical necessity for building the capability of storing massive amounts of data in its native format for future uses.
As per an Aberdeen survey, businesses with data lake capabilities outperformed their peers by 9% in organic revenue growth.
Department heads and data scientists can perform new types of analytics, such as machine learning, over relatively new sources of data such as social media, log files, internet-connected devices, etc. The new insights can enable these leaders to identify new possibilities and challenges and build a new competitive mode in their respective industries.
What are data lake use cases?
A robust data lake architecture translates into robust foundations for advanced analytics and artificial intelligence (AI); therefore, more and more businesses across industries are using them to drive data value, decision-making, and business revenue.
- Banking and financial services (BFSI):The banking and financial services industry deals with massive amounts of customer and business data that they are required to handle with utmost care.
To seamlessly and cost-effectively store all the data in one place makes a data lake a critical asset to have.
The data lake architecture or setup helps these companies improve customer insights, enable real-time fraud detection, support advanced analytics for risk assessment, and ensure regulatory compliance. Investment firms utilize real-time market data for portfolio risk management through machine learning. - Media and entertainment: Data lakes are increasingly becoming an indispensable tool for media and entertainment companies to improve viewer experiences and revenue streams.
The strategic use of data lakes eventually fortifies a streaming service’s capability to facilitate more personalized content recommendations and generate more opportunities for targeted advertising to drive revenues.
Additionally, data lakes can also assist in safeguarding intellectual property and ensuring compliance with licensing agreements. - Telecommunications: Players in the telecommunications industry can leverage data lakes to improve network performance, eliminate downtime with predictive maintenance, and improve customer experiences.
Adopting a data lake architecture can also help improve network security by detecting and mitigating cybersecurity threats, ensuring data integrity and customer satisfaction while driving revenue growth.
Setting up a data lake
A data lake setup can be achieved in multiple permutations and combinations. So, for example, you can set up a data lake in the cloud or build it up entirely on-premises. You can choose to use multi-cloud for the purpose or build it part cloud and part on-premises.
Setting up an on-premises data lake may require significant effort and investment on your part. As more and more organizations are making a shift toward the cloud, building a data lake right in the cloud can be a faster and more rewarding endeavor.
A data lake setup has to be a deliberate decision on your part and must be aligned with your comprehensive data strategy. Whether you need a data lake or not can be a good starting point. To solve the puzzle, asking yourself a list of questions can help.
- What type of data are you working with?
- How do you plan to use the data that you’re generating?
- How complex is your data acquisition process?
- What type of tools and skills exist within your organization?
- What is your strategy for data management and governance?
If you believe setting up a data lake architecture can help resolve issues and bolster new growth and collaboration opportunities across your organization, you can set up one either on-premises or in the cloud.
For cloud enthusiasts, AWS Cloud, Azure, and Google Cloud provide numerous choices that will allow you to build fast and reap the benefits of a highly scalable and cost-effective data storage solution.
Getting started with data lakes
Data lakes can have a transformative impact on your organization’s ability to ingest, store, and process data to inform decisions that drive business agility and impact bottom lines.
By allowing the storage of diverse and unstructured data in its raw form, it empowers businesses to harness the full spectrum of their data resources for insights and decision-making.
Here at Kellton, we have been helping our clients with their data challenges for years. Depending on the specific business goals and challenges, our expertise lies in cost-effective and scalable data lake development, ensuring data quality and enabling efficient data processing and analysis.
With our next-generation data management and storage solutions, you can accelerate the entire process of setting up data lakes, leading to more informed strategic decisions, improved operational efficiencies, and a competitive edge in today's data-driven landscape.
We understand that every organization is unique, and our tailored approach ensures that a data lake implementation aligns perfectly with specific business objectives, thereby maximizing its value and impact.
To strategically build your case for a modern data lake within your organization, please connect with our data experts.
Let's talk

